Contents
Intro
In Broadway, RabbitMQ, and the Rise of Elixir Part 1 we covered what exactly a message queue is and when it is appropriate to use one. We also put together the foundation for our application which will mine data from the HackerNews Firebase API. In the final part of this series, we will be setting up our Broadway pipelines, a GenServer that will generate IDs for us to process, and some database related modules that will allow us to persist our results for later analysis. Part 2 assumes that you have already gone through Part 1 and have the code at a point where we can jump right in. If you want to checkout the companion code and fast forward to this point, do the following:
$ git clone https://github.com/akoutmos/elixir_popularity.git
$ cd elixir_popularity
$ git checkout 7effd277c61656d67bd5fe970e20f5fc8dda53ca
Without further ado, let’s dive right into things!
Step 5: Create GenServer to populate RabbitMQ with HackerNews IDs - commit
In order to get the data that we need from the HackerNews API, we’ll need to have some way of controlling what HackerNews items we will be fetching (for more details on the HackerNews API visit https://github.com/HackerNews/API). Like most problems we are trying to solve, we have a couple of options here as to how we can go about doing this. One option would be to create a GenStage custom producer [1] that will provide a valid HackerNews ID whenever downstream Broadway stages require work to do. Another option (and the route we will be going) is to have RabbitMQ be the source of work that downstream Broadway stages consume from and have another mechanism in place to fill RabbitMQ with work to process. The mechanism in this case is a GenServer that routinely enqueues batches of HackerNews IDs when the number of enqueued messages drops below a certain threshold. Just to be clear, either design will achieve the same result, but we are going the GenServer route so that:
- We can play around with GenServers :)
- We can have our entire data processing pipeline be controlled by RabbitMQ for the purposes of learning
With all that out of the way, let’s create a new module ElixirPopularity.HackerNewsIdGenerator in the file
lib/hn_id_generator.ex. The module will have the following contents:
defmodule ElixirPopularity.HackerNewsIdGenerator do
use GenServer
require Logger
alias ElixirPopularity.RMQPublisher
# ---------------- Initialization Functions ----------------
def start_link(state) do
GenServer.start_link(__MODULE__, state, name: __MODULE__)
end
@impl true
def init(options) do
state = Map.put(options, :timer_ref, nil)
{:ok, state}
end
# ---------------- Public Functions ----------------
def start_generating, do: GenServer.call(__MODULE__, :start_generating)
def stop_generating, do: GenServer.call(__MODULE__, :stop_generating)
# ---------------- Callback Functions ----------------
@impl true
def handle_info(:poll_queue_size, %{current_id: current_id, end_id: end_id} = state) when current_id > end_id do
# All done with the configured work, nothing else to do
Logger.info("No more HackerNews IDs to generate. My work is done. I can rest now.")
{:stop, :normal, state}
end
def handle_info(:poll_queue_size, state) do
# Get the size of the queue using the GenRMQ module
queue_size = RMQPublisher.hn_id_queue_size()
# Determine if more HackerNews items IDs need to be put on the queue
new_current_id =
if queue_size < state.generate_threshold do
upper_range = min(state.current_id + state.batch_size, state.end_id)
Logger.info("Enqueuing HackerNews items #{state.current_id} - #{upper_range}")
# Publish all the new HackerNews items IDs
state.current_id..upper_range
|> Enum.each(fn hn_id ->
RMQPublisher.publish_hn_id("#{hn_id}")
end)
upper_range + 1
else
Logger.info("Queue size of #{queue_size} is greater than the threshold of #{state.generate_threshold}")
state.current_id
end
new_state =
state
|> Map.put(:current_id, new_current_id)
|> Map.put(:timer_ref, schedule_next_poll(state.poll_rate))
{:noreply, new_state}
end
@impl true
def handle_call(:start_generating, _from, state) do
send(self(), :poll_queue_size)
{:reply, :ok, state}
end
@impl true
def handle_call(:stop_generating, _from, state) do
Process.cancel_timer(state.timer_ref)
new_state = %{state | timer_ref: nil}
{:reply, :ok, new_state}
end
defp schedule_next_poll(poll_rate) do
Logger.info("Scheduling next queue poll")
Process.send_after(self(), :poll_queue_size, poll_rate)
end
end
We’ll also want this GenServer to be started along with our application so we need to update our
lib/elixir_popularity/application.ex file to start the GenServer along with the required options as its initial
state. Let’s go ahead and make those changes now:
def start(_type, _args) do
children = [
...
%{
id: ElixirPopularity.HackerNewsIdGenerator,
start:
{ElixirPopularity.HackerNewsIdGenerator, :start_link,
[
%{
current_id: 2_306_006,
end_id: 21_672_858,
generate_threshold: 50_000,
batch_size: 30_000,
poll_rate: 30_000
}
]},
restart: :transient
}
]
...
end
Feel free to adjust the settings of the GenServer to suite your needs and setup. An important thing to note here before
moving on is that the restart policy for the GenServer is :transient. The reason for this being that we do no want the
GenServer to restart automatically via the supervisor if we kill it ourselves normally (which we do in the
handle_info/2 handler if there are no more IDs to enqueue). Below is a brief overview of the fields in the map and
what they do:
current_id: What the current ID to be generated is. In the case of initializing the GenServer, it is the starting ID (José’s first post about Elixir).end_id: What ID should be the stopping point for the GenServer (the last post of November 2019).generate_threshold_id: Below what number of messages should the GenServer enqueue additional IDs.batch_size: How many IDs should be enqueued at a single time.poll_rate: How often should the GenServer check the queue size in RabbitMQ.
We can test that our GenServer is working correctly by starting up IEX and starting the polling. It is also useful to
have the RabbitMQ admin dashboard open to see the messages queue up (if you are running the docker compose stack via
docker-compose up the admin dashboard should be available at http://localhost:15672). Run iex -S mix and do
the following to verify:
iex(1) ▶ ElixirPopularity.HackerNewsIdGenerator.start_generating()
:ok
iex(2) ▶ [info] Enqueuing HackerNews items 2306006 - 2336006
[info] Scheduling next queue poll
[info] Enqueuing HackerNews items 2336007 - 2366007
[info] Scheduling next queue poll
[info] Queue size of 60002 is greater than the threshold of 50000
[info] Scheduling next queue poll
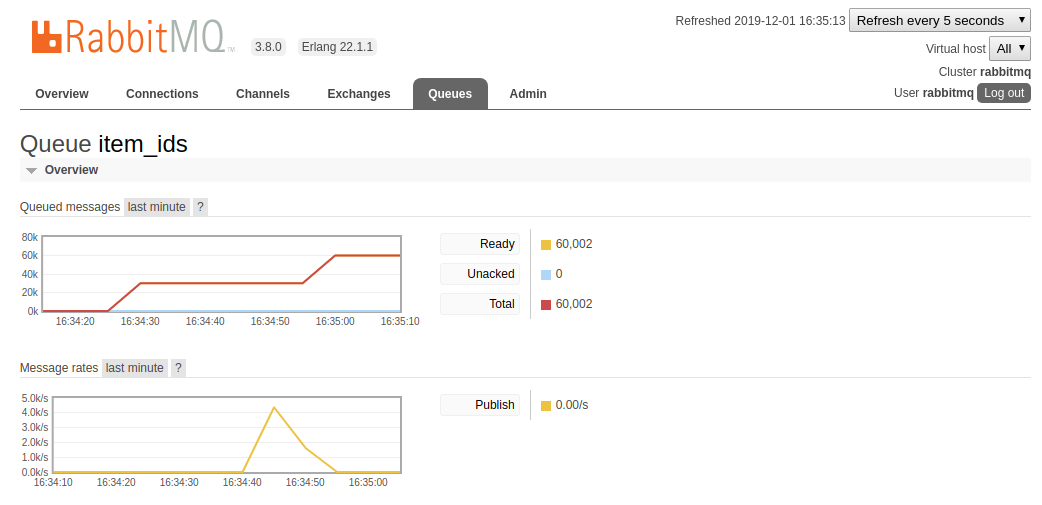
Be sure to purge the queue from the admin dashboard after running this quick sanity check so that we do not double process HackerNews items when we run the pipeline at the end of the tutorial.
Step 6: Create Broadway consumer to process HackerNews IDs - commit
With our GenServer in place generating HackerNews item IDs, it is time to create the first stage in our Broadway pipeline to consume those messages. This stage of the pipeline will work as follows:
- It consume a message from RabbitMQ containing the ID of the item it needs to fetch.
- It then will fetch the HackerNews item using the
ElixirPopularity.HackernewsApimodule we wrote in Part 1. - Finally it batches up a group of results and publishes them to another RabbitMQ queue.
Create a new file at lib/hackernews_id_processor.ex with the following contents:
defmodule ElixirPopularity.HackernewsIdProcessor do
use Broadway
alias Broadway.Message
alias ElixirPopularity.{HackernewsApi, RMQPublisher}
def start_link(_opts) do
Broadway.start_link(__MODULE__,
name: __MODULE__,
producers: [
default: [
module:
{BroadwayRabbitMQ.Producer,
queue: RMQPublisher.item_id_queue_name(),
connection: [
username: "rabbitmq",
password: "rabbitmq"
]},
stages: 1
]
],
processors: [
default: [
stages: 100
]
],
batchers: [
default: [
batch_size: 10,
batch_timeout: 10_000,
stages: 2
]
]
)
end
@impl true
def handle_message(_processor, message, _context) do
Message.update_data(message, fn hn_id ->
{hn_id, HackernewsApi.get_hn_item(hn_id)}
end)
end
@impl true
def handle_batch(_batcher, messages, _batch_info, _context) do
encoded_payload =
messages
|> Enum.reject(fn
%Message{data: {_id, :error}} -> true
_ -> false
end)
|> Enum.map(fn %Message{data: {id, item}} ->
%{
id: id,
item: Map.from_struct(item)
}
end)
|> Jason.encode!()
RMQPublisher.publish_hn_items(encoded_payload)
messages
end
end
There is quite a lot going on here so let’s break it down function by function. In our start_link/1 function we define
how our Broadway stage will operate and how it is initialized. It is broken up into 3 logical parts, each with their own
configuration:
- Producers: This section of the configuration tells Broadway how to connect to a valid Broadway message producer. In
this case since we are using RabbitMQ as our Broadway producer, we will use the
BroadwayRabbitMQ.Producermodule and pass it the information necessary to connect to our RabbitMQ instance (for a production application do not store the user name and password in code like I have above ;)). In addition, we have configured the producer stage to only have 1 running instance (we’ll see this later when we visualize our supervision tree). - Processors: The processors section is responsible for executing your
handle_message/3function and in this case, the only option that we are leveraging is thestagesoption which allows us to specify how many concurrent processors we will have running. In this case, we will have 100 BEAM processes running concurrently and reaching out to the HackerNews API for data (if you recall we also have a hackney pool defined in ourlib/elixir_popularity/application.exfile with the same exact value ;)). - Batchers: This section specifies how many batching processes should be executing concurrently and what the batch size
and timeout will be for the group of messages that they receive. In this case, the
handle_batch/4function will be invoked either when 10 messages have been processed byhandle_message/3or when the timeout threshold has been hit.
After the start_link/1 function we have the handle_message/3 function which is responsible for calling the
HackerNews API module that we wrote in Part 1 and updating the Broadway message with the fetched information. After
that, we have the handle_batch/4 function which will aggregate a group of messages, filter out invalid messages, and
then publish the serialized group of messages to RabbitMQ using our gen_rmq based publisher.
Our last step for this step will be to add this Broadway related module to our application supervision tree. To do that
add the following to your lib/elixir_popularity/application.ex file:
def start(_type, _args) do
children = [
...
ElixirPopularity.HackernewsIdProcessor
]
...
end
To test that everything is working as expected, open up an IEX session with iex -S mix and run the below code. To
visualize the queue in RabbitMQ, open up the admin dashboard again and navigate to the bulk_item_data queue.
iex(1) ▶ ElixirPopularity.HackerNewsIdGenerator.start_generating()
:ok
iex(2) ▶ [info] Enqueuing HackerNews items 2306006 - 2336006
[info] Scheduling next queue poll
iex(2) ▶ ElixirPopularity.HackerNewsIdGenerator.stop_generating()
:ok
We start and stop the ID generator GenServer as the rest of our pipeline has yet to be built and there is no reason to keep it
running. But as we can see from the below RabbitMQ admin dashboard screenshots, our item_ids queue is being drained at
a rate of about ~800 messages per second (this means that we are fetching about 800 items from the HackerNews API
every second!!).

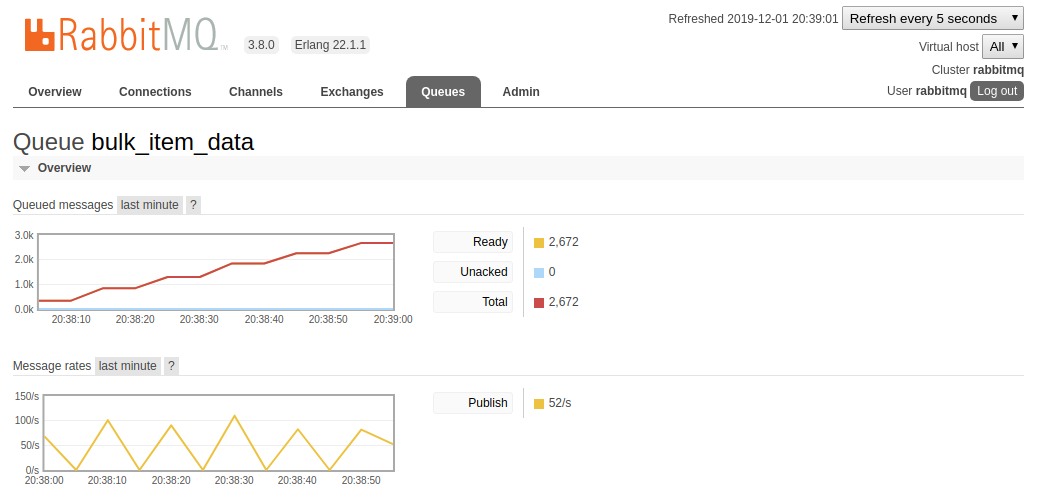
With the data fetching side of the pipeline complete, it is time to work on the analytics side of the pipeline and
search for our desired key terms. You should again purge your queues (both the item_ids and bulk_item_data) from the
admin dashboard as you did before.
Step 7: Setup database related modules - commit
Before we create our next Broadway module, we will need to set up some supporting database related modules and
migrations. From the terminal go ahead and run mix ecto.gen.migration create_stats_table and then add the following to
the migration file that is in priv/repo/migrations/:
defmodule ElixirPopularity.Repo.Migrations.CreateStatsTable do
use Ecto.Migration
def change do
create table(:hn_stats) do
add :item_id, :string
add :item_type, :string
add :language, :string
add :date, :date
add :occurances, :integer
end
create index(:hn_stats, [:date])
create index(:hn_stats, [:language])
create index(:hn_stats, [:item_id])
create index(:hn_stats, [:item_type])
end
end
After that is in place, you can run mix ecto.create and mix ecto.migrate from the terminal (granted your Postgres
container is running via Docker Compose) and your table should be created and ready to go. Next we will want to have our
Ecto schema in place so that the next stage in the Broadway pipeline can write our changesets to the database. Create a
file lib/hn_stats.ex and add the following to it:
defmodule ElixirPopularity.HNStats do
use Ecto.Schema
import Ecto.Changeset
schema "hn_stats" do
field :item_id, :string
field :item_type, :string
field :language, :string
field :date, :date
field :occurances, :integer
end
def changeset(hn_stats, params \\ %{}) do
all_fields = ~w(item_id item_type language date occurances)a
hn_stats
|> cast(params, all_fields)
|> validate_required(all_fields)
end
end
With that in place, we are ready to write the next stage of the data processing pipeline!
Step 8: Create Broadway consumer to process HackerNews items - commit
Similarly to step 6, we need to create a module that uses Broadway to consume the messages published from the
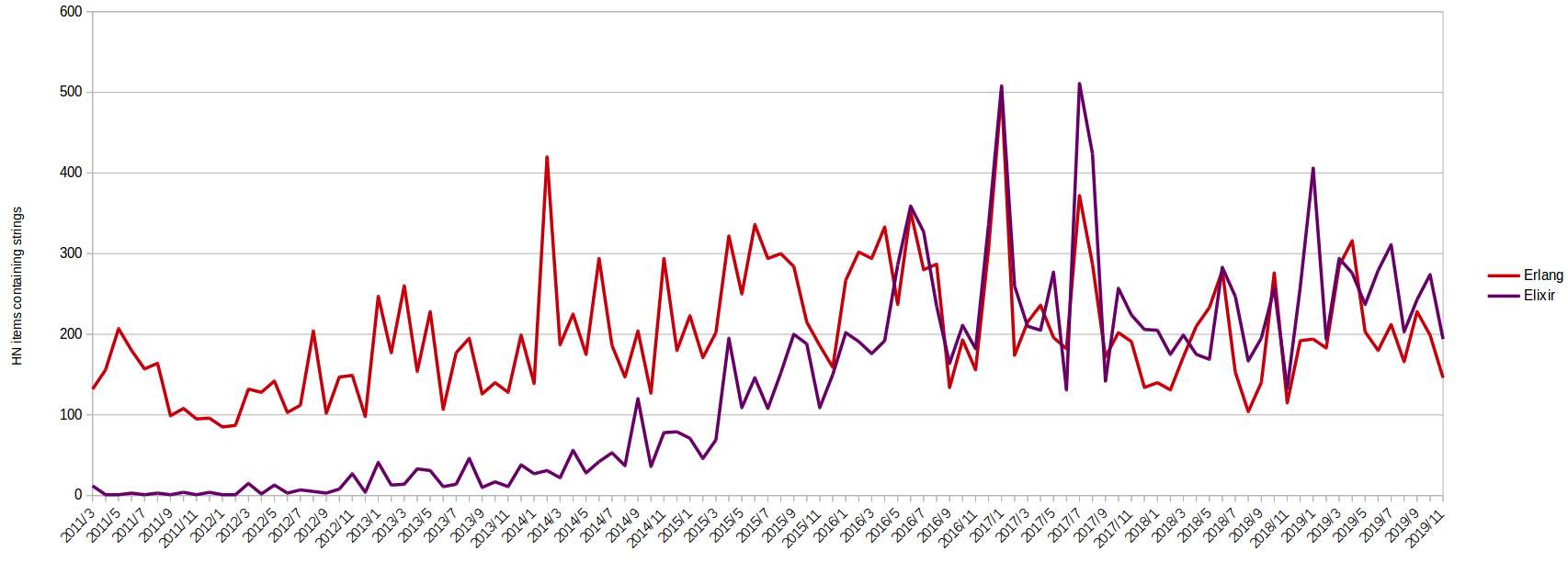
previous pipeline stage. Then we will scan the retrieved text for the strings “elixir” and “erlang” (case insensitive of
course) and see how the occurrence of the words has changed over time since José Valim’s original post in March 2011.
Create a new file at lib/hackernews_payload_processor.ex and give it the following contents:
defmodule ElixirPopularity.HackernewsPayloadProcessor do
use Broadway
alias Broadway.Message
alias ElixirPopularity.{HNStats, Repo}
def start_link(_opts) do
Broadway.start_link(__MODULE__,
name: __MODULE__,
producers: [
default: [
module:
{BroadwayRabbitMQ.Producer,
queue: ElixirPopularity.RMQPublisher.bulk_item_data_queue_name(),
connection: [
username: "rabbitmq",
password: "rabbitmq"
]},
stages: 1
]
],
processors: [
default: [
stages: 20
]
]
)
end
def handle_message(_processor, %Message{data: data} = message, _context) do
data
|> Jason.decode!()
|> Enum.map(fn entry ->
summarize_data(entry)
end)
|> Enum.filter(fn summary ->
summary.language_present
|> Map.values()
|> Enum.member?(true)
end)
|> Enum.each(fn entry ->
date = entry.date
hn_id = entry.id
type = entry.type
Enum.each(entry.language_present, fn
{lang, true} ->
%HNStats{}
|> HNStats.changeset(%{
item_id: hn_id,
item_type: type,
language: Atom.to_string(lang),
date: date,
occurances: 1
})
|> Repo.insert()
{_lang, false} ->
nil
end)
end)
message
end
defp summarize_data(hn_item) do
%{
id: hn_item["id"],
date: hn_item["item"]["time"],
type: hn_item["item"]["type"],
language_present: language_check(hn_item["item"])
}
end
defp language_check(%{"type" => "story", "text" => text}) when not is_nil(text) do
process_text(text)
end
defp language_check(%{"type" => "story", "title" => text}) when not is_nil(text) do
process_text(text)
end
defp language_check(%{"type" => "comment", "text" => text}) when not is_nil(text) do
process_text(text)
end
defp language_check(%{"type" => "job", "text" => text}) when not is_nil(text) do
process_text(text)
end
defp process_text(text) do
[elixir: ~r/elixir/i, erlang: ~r/erlang/i]
|> Enum.map(fn {lang, regex} ->
{lang, String.match?(text, regex)}
end)
|> Map.new()
end
defp language_check(_item) do
%{
elixir: 0,
erlang: 0
}
end
end
This module should look very familiar as it is structured the same way as the previous Broadway module. One thing to
note is that this module does not perform any kind of batching like the previous module. Instead, it retrieves the
batched messages from RabbitMQ, decodes the JSON payload, then proceeds to search for our desired strings, and then
finally writes to the database if it finds anything. The language_check/1 functions may seem a little random, but if you look
at [2] you will see that we are pattern matching the structure of the HackerNews item structure to get out the relevant
text fields.
Lastly, we will need to add this new module to our supervision tree in lib/elixir_popularity/application.ex:
def start(_type, _args) do
children = [
...
ElixirPopularity.HackernewsPayloadProcessor
]
...
end
Step 9: Run the data collection/processing pipeline
With everything in place, it is now pretty straight forward to get everything going and should be completely hands free until all the data has been fetched, analyzed, and persisted. Before we actually run the pipeline, let’s review the structure of our data processing pipeline through the magic of ASCII diagram:
GenServer Broadway
HackerNewsIdGenerator ----> RabbitMQ ----> HackernewsIdProcessor ----+
|
+-----------------------------------------------------------------+
|
V Broadway
RabbitMQ ----> HackernewsPayloadProcessor ----> Postgres
As we can see, the GenServer that we wrote kicks off the processing pipeline by producing IDs and enqueuing them into
RabbitMQ. After that, as the Broadway modules consume and produce messages it will allow the GenServer to create more
item IDs. Without further ado…let’s kick off the processing pipeline and see how it goes! Open up an IEX session with
iex -S mix and run the following:
iex(1) ▶ ElixirPopularity.HackerNewsIdGenerator.start_generating()
:ok
iex(2) ▶ [info] Enqueuing HackerNews items 2306006 - 2336006
[info] Scheduling next queue poll
[info] Enqueuing HackerNews items 2336007 - 2366007
[info] Scheduling next queue poll
[info] Enqueuing HackerNews items 2366008 - 2396008
[info] Scheduling next queue poll
[info] Enqueuing HackerNews items 2396009 - 2426009
[info] Scheduling next queue poll
About 12 hours later...
[info] Queue size of 60704 is greater than the threshold of 50000
[info] Scheduling next queue poll
[info] Enqueuing HackerNews items 21656651 - 21672858
[info] Scheduling next queue poll
[info] No more HackerNews IDs to generate. My work is done. I can rest now.
On my Linux machine and with my home internet connection I was able to work through 19,366,852 HackerNews entries in about 12 hours at a relatively consistent rate of about 450 messages per second as can be seen here from the Grafana chart:

We can also see in the below Grafana chart that our item ID queue was able to maintain a healthy number of pending items in queue ready for processing (thanks to our GenServer producing IDs):

The last thing I would like to do is visualize is the supervision tree of the running application. The image is rather
large even with the number of ID processors down to 10 from 100 (sorry mobile users). The important thing to note is
that the number of BEAM processes matches what was defined in the stages section of the Broadway configuration. You
may also notice how well architected Broadway is in that it also put all of our worker processes under their own
supervision processes. The reason for this being so that they could be restarted if an error occurred and took down the
worker process.

Step 10: Visualizing our results
With all the technical goodies wrapped up, it is time to see the fruits of our labor! Our goal from the start of this was to process ~20 million HackerNews items and see how the strings “elixir” and “erlang” have trended over time. The Postgres queries that I used to fetch the data are (remember we only counted how many HackerNews items had at least 1 occurrence of the desired strings not how many times the strings were found throughout all the items):
-- Elixir query
SELECT date_part('year', date) as year, date_part('month', date) as month, language, sum(occurances)
FROM hn_stats
WHERE language='elixir'
GROUP BY year, month, language
ORDER BY year, month;
-- Erlang query
SELECT date_part('year', date) as year, date_part('month', date) as month, language, sum(occurances)
FROM hn_stats
WHERE language='erlang'
GROUP BY year, month, language
ORDER BY year, month;
Using the data, I plotted the results which yielded the chart below (I used LibreOffice Calc for those who are interested):
Closing thoughts
Well done and thanks for sticking with me to the end! We covered quite a lot of ground and hopefully you picked up a couple of cool tips and tricks along the way. To recap, in Part 2 of our RabbitMQ+Broadway series we wrapped up our data processing pipeline by creating the required Broadway modules to process our data. We also wrote a GenServer to create item IDs for us to process all using RabbitMQ to coordinate the workload. We finally persisted our data to Postgres and used some simple SQL statements to summarize our data and get it ready for plotting. We also leveraged Prometheus and Grafana to keep an eye on our data processing pipeline and ensure that our performance was consistent and met our expectations. As a result, we were able to see that over time Elixir has been trending upwards and has finally caught up to Erlang in terms of how often it is mentioned on HackerNews.
Feel free to leave comments or feedback or even what you would like to see in the next tutorial. Merry Christmas and Happy Holidays! See you all in 2020 :).
Additional Resources
Below are some additional resources if you would like to deep dive into any of the topics covered in the post.
comments powered by Disqus