Contents
Intro
In OTP as the Core of Your Application Part 1 we covered what exactly the Actor Model is, how it is implemented in the Erlang Virtual machine (or BEAM for short), and some of the benefits of this kind of pattern. In the final part of this series, we’ll be implementing the Actor Model specific parts of our application, putting together a simple stress test tool, and comparing the performance characteristics of a traditional database centric application where every request is dependant on a round trip to the database. Part 2 assumes that you have already gone through Part 1 and have the code at a point where we can jump right in. If you want to checkout the companion code and fast forward to this point, do the following:
$ git clone https://github.com/akoutmos/book_store.git
$ cd book_store
$ git checkout ad5d6aad6cf092e71804bbf097b7ccf4122ae13b
Without further ado, let’s dive right into things!
Step 4: Creating a Book Process Registry - commit
As outlined in Part 1 of this series, we will be using a single GenServer per book in our book store. The reason for this being that each book is in essence its own “Actor” and should be kept isolated from all other books in the book store. Each book Actor (or in the case of the BEAM, a process) will be able to maintain its own inventory count and can atomically allocate inventory to orders that come in. In order to invoke the correct GenServer process, we require an additional mechanism to correlate a book UUID with a GenServer process ID (or PID for short). Since processes on the BEAM are addressable generally by their PID, the mechanism that we will use to lookup PIDs from UUIDs is the Registry [1].
I suggest going through the Registry documentation to get a deep dive into how the Registry works, but here are some of the high level details that our of importance to us for this tutorial:
- Registry is a local key-value store for PIDs (if you require a distributed registry then Swarm or Horde.Registry are most likely what you are looking for).
- PIDs are removed from the key-value store when the associated process terminates.
With these things in mind, let’s create a file lib/book_store/book_registry.ex with the following contents:
defmodule BookStore.BookRegistry do
def child_spec do
Registry.child_spec(
keys: :unique,
name: __MODULE__,
partitions: System.schedulers_online()
)
end
def lookup_book(book_id) do
case Registry.lookup(__MODULE__, book_id) do
[{book_pid, _}] ->
{:ok, book_pid}
[] ->
{:error, :not_found}
end
end
end
Our BookStore.BookRegistry module only has two functions. The child_spec/0 function specifies the child
specification for our Registry. We will be leveraging this in our application.ex file so that our Registry is started
correctly. Our second function, lookup_book/1, does what we previously discussed. It uses our instantiated Registry to
look up if a PID exists for the provided UUID. If it does exist, we return it in an :ok tuple, else we return an
:error tuple. We will be leveraging this Registry any time we need to interact with our running book processes so we
can invoke the correct process.
With our Registry implemented, all that is left is to start it with out application. To do so, open up
lib/book_store/application.ex and add the following:
def start(_type, _args) do
children = [
...
# Start the Book Store Registry
BookStore.BookRegistry.child_spec(),
...
]
...
end
Step 5: Creating a Book Process DynamicSupervisor - commit
In addition to our Registry, we also require a mechanism that can dynamically supervise book processes as they are
created and terminated. Specifically, the number of books that we have in our book store can change throughout the life
cycle of our application as books are added and removed from the to the store. In addition, if we ever encounter a bug
in our code and a particular book process crashes, it would be nice if there were a mechanism is place to restart that
book process from a fresh state. The tool that I have been describing thus far is the DynamicSupervisor [2]! While these
are the high level details, I suggest looking at the documentation to get a more thorough understanding of what a
DynamicSupervisor is and how it works. Let’s create a file lib/book_store/book_dynamic_supervisor.ex with the
following contents:
defmodule BookStore.BookDynamicSupervisor do
use DynamicSupervisor
alias BookStore.Books.{Book, BookProcess}
def start_link(opts) do
DynamicSupervisor.start_link(__MODULE__, opts, name: __MODULE__)
end
@impl true
def init(_opts) do
DynamicSupervisor.init(strategy: :one_for_one)
end
def add_book_to_supervisor(%Book{} = book) do
child_spec = %{
id: BookProcess,
start: {BookProcess, :start_link, [book]},
restart: :transient
}
{:ok, _pid} = DynamicSupervisor.start_child(__MODULE__, child_spec)
end
def all_book_pids do
__MODULE__
|> DynamicSupervisor.which_children()
|> Enum.reduce([], fn {_, book_pid, _, _}, acc ->
[book_pid | acc]
end)
end
end
Let’s quickly review what we have in our DynamicSupervisor module. Our start_link/1 and init/1 functions define how
to start our DynamicSupervisor and will be used in our application.ex file. Our add_book_to_supervisor/1 function
takes a Book struct as its only argument and starts a respective BookProcess for that book. We will be leveraging
this function any time we need to start a GenServer that encapsulates our book data. Our last function all_book_pids/0
returns a list of all the PIDs that are currently being supervised by the DynamicSupervisor. In effect, this replaces
a call that we would make to the database to fetch all of the books in the DB (SELECT * FROM books; if you will).
With our DynamicSupervisor implemented, all that is left is to start it with out application. To do so, open up
lib/book_store/application.ex and add the following:
def start(_type, _args) do
children = [
...
# Start the Book DynamicSupervisor
BookStore.BookDynamicSupervisor,
...
]
...
end
With that in place, it is time to write the BookProcess GenServer that we referenced in our DynamicSupervisor.
Step 6: Creating the Book Process GenServer - commit
Now that the Registry and the DynamicSupervisor are both in place, all that we require is to have the actual GenServer
implementation that will maintain our book state. Let’s create that file at lib/book_store/books/book_process.ex with
the following contents:
defmodule BookStore.Books.BookProcess do
use GenServer, restart: :transient
require Logger
alias BookStore.Repo
alias BookStore.Books.Book
alias Ecto.Changeset
def start_link(%Book{} = book) do
GenServer.start_link(__MODULE__, book,
name: {:via, Registry, {BookStore.BookRegistry, book.id}}
)
end
@impl true
def init(%Book{} = state) do
{:ok, state}
end
@impl true
def handle_call(:read, _from, %Book{} = state) do
{:reply, state, state}
end
@impl true
def handle_call({:update, attrs}, _from, %Book{} = state) do
state
|> update_book(attrs)
|> case do
{:ok, %Book{} = updated_book} ->
{:reply, updated_book, updated_book, {:continue, :persist_book_changes}}
error ->
{:reply, error, state}
end
end
@impl true
def handle_call(:order_copy, _from, %Book{quantity: 0} = state) do
{:reply, :no_copies_available, state}
end
@impl true
def handle_call(:order_copy, _from, %Book{quantity: quantity} = state) do
state
|> update_book(%{quantity: quantity - 1})
|> case do
{%Book{} = updated_book, changeset} ->
{:reply, :ok, updated_book, {:continue, {:persist_book_changes, changeset}}}
error ->
{:reply, error, state}
end
end
@impl true
def handle_continue({:persist_book_changes, changeset}, state) do
Repo.update(changeset)
{:noreply, state}
end
defp update_book(book, attrs) do
book
|> Book.changeset(attrs)
|> case do
%Changeset{valid?: true} = changeset ->
updated_book = Changeset.apply_changes(changeset)
{updated_book, changeset}
error_changeset ->
{:error, error_changeset}
end
end
end
There is quiet a lot here so let’s unpack this slowly. Firstly, we make use of the :restart GenServer option and set
it to :transient given that we want this GenServer to be able to stop under normal conditions (i.e we don’t want it to
restart the GenServer if we stopped it with a :normal reason). Our start_link/1 function also has some special
goodness in it. If you look closely at the :name option, we pass in a :via tuple instead of a regular old process
name. The significance of this is that it instructs the supervisor to start the process, but instead of leveraging the
default local process registry, it will invoke your provided Registry (in this case BookStore.BookRegistry). For more
information on this topic definitely checkout [3] and [4].
Our next collection of functions are our handle_call/3 callback implementations. Our :read version merely returns
the state of the GenServer (which happens to be the current state of the book). Any time that a user performs a read
against our system, we merely return the state of the process. Contrast this with a typical 3-tier application where we
would instead make a network request to a database, deserialize the response, convert that response to a Book struct,
and then carry on with servicing the request. What this means for our application is that we should be able to realize
immense performance gains while still having the ergonomics of a database resource (i.e multiple reads/writes to the
same resource still happen serially and atomically). Think of this as a living breathing cache where the persistence
layer is merely used as a backup and the state of the process is what the user is actually interacting with.
To further this idea, in our :order_copy pattern match handle_call/3 functions, instead of dealing directly with the
database, we simply validate our changeset using the updated_book/2 private function, and then return that data to the
GenServer caller, immediately unblocking them. In order to ensure that the state of the database aligns with the state
of the GenServer, we pass the {:continue, {:persist_book_changes, changeset}} tuple as the 4th element in our
handle_call/3 reply tuple. What this does is tell the GenServer that as soon as this invocation of handle_call/3
function completes, it must run the handle_continue/2 callback.
In our case our handle_continue/2 function that matches on {:persist_book_changes, changeset} simply writes the
state to the database. While this may seen trivial, it has very important implications. What this does is ensure that
our HTTP requests coming in are serviced out-of-band from our database interactions. This means that requests can be
serviced orders of magnitude faster given that there are no external resources that need to be called for the purposes
of servicing the HTTP request. In addition, we are able to maintain database state parity given that our
handle_continue/2 callback ensures that it is called immediately after a state change. All other requests in the
process mailbox are deferred until the database is updated.
With our BookProcess wrapped up, let’s start working on our Phoenix context for books and our HTTP endpoints.
Step 7: Creating our Phoenix Books Context and HTTP Endpoints - commit
Let’s start by opening up our lib/book_store_web/router.ex file and add some routes:
scope "/api", BookStoreWeb do
pipe_through :api
resources "/books", BookController, only: [:index, :show] do
post "/order", BookController, :order
end
end
With that in place, let’s create our controller at lib/book_store_web/controllers/book_controller.ex with the
following contents:
defmodule BookStoreWeb.BookController do
use BookStoreWeb, :controller
alias BookStore.Books
alias BookStore.Books.Book
def index(conn, _params) do
# books = Books.actor_all()
books = Books.all()
conn
|> json(books)
end
def show(conn, %{"id" => book_id}) do
# book = Books.actor_read(book_id)
book = Books.read(book_id)
case book do
%Book{} = book ->
conn
|> json(book)
_ ->
conn
|> put_status(404)
|> json(%{error: "Not found"})
end
end
def order(conn, %{"book_id" => book_id}) do
# status = Books.actor_order(book_id)
status = Books.order(book_id)
case status do
:ok ->
conn
|> put_status(201)
|> json(%{status: "Order placed"})
:no_copies_available ->
json(conn, %{status: "Not enough copies on hand to complete order"})
{:error, :not_found} ->
conn
|> put_status(404)
|> json(%{error: "Not found"})
end
end
end
With our controller in place, all that remains is to create our Books context with our appropriate calls. As you
probably noticed, for every call to a Books context function, we also have a actor_ prefixed call. Our two functions
will have the same interface so it should be just a matter of swapping out the calls when it comes to for benchmarking
so that all other things are equal.
Below is the code for our Books context module that resides at lib/book_store/books.ex:
defmodule BookStore.Books do
import Ecto.Query, warn: false
alias BookStore.Books.Book
alias BookStore.{BookDynamicSupervisor, BookRegistry, Repo}
# All the OTP/actor model based calls
def actor_all do
BookDynamicSupervisor.all_book_pids()
|> Enum.reduce([], fn pid, acc ->
case actor_read(pid) do
%Book{} = book -> [book | acc]
_ -> acc
end
end)
end
def actor_read(book_pid) when is_pid(book_pid) do
book_pid
|> GenServer.call(:read)
|> case do
%Book{} = book -> book
_ -> {:error, :not_found}
end
end
def actor_read(book_id) do
book_id
|> BookRegistry.lookup_book()
|> case do
{:ok, pid} -> GenServer.call(pid, :read)
error -> error
end
end
def actor_order(book_id) do
book_id
|> BookRegistry.lookup_book()
|> case do
{:ok, pid} -> GenServer.call(pid, :order_copy)
error -> error
end
end
# Database only calls
def all do
Repo.all(Book)
end
def read(id) do
case Repo.get(Book, id) do
%Book{} = book ->
book
_ ->
{:error, :not_found}
end
end
def order(book_id) do
{_, result} =
Repo.transaction(fn ->
case Repo.get(Book, book_id) do
%Book{quantity: 0} ->
:no_copies_available
%Book{quantity: quantity} = book ->
update_book(book, %{quantity: quantity - 1})
:ok
_->
{:error, :not_found}
end
end)
result
end
def update_book(%Book{} = book, attrs) do
book
|> Book.changeset(attrs)
|> Repo.update()
end
def create(attrs \\ %{}) do
%Book{}
|> Book.changeset(attrs)
|> Repo.insert()
end
end
Step 8: Hydrating Our Application State - commit
With our endpoints and Phoenix Context in place, all that is left is to hydrate our application on startup so that we are able to interact with our GenServers from the get-go. We will attack this problem by doing the following:
- On application start, we will fetch all of the books from the database
- We will start a GenServer for each book using our DynamicSupervisor and Registry
- Once the startup process is complete, the state hydration GenServer will die
- The rest of the application supervision tree will be allowed to proceed
Given our dataset is rather small (only about 1,100 books), we can easily spawn a GenServer for each book right from the
start. If our problem domain deals with a very large amount of data (order of hundreds of thousands/millions), you may
require a more intelligent means of dealing with this. For example, you could start a GenServer only when a resource
is requested and have it sit around for a certain window of inactivity (this can easily be accomplished with
Process.send_after/3 and Process.cancel_timer/2). That way resources that are in high demand have the performance
benefits of running in a GenServer, while resources that are rarely used don’t become a burden on the system.
With that said, let’s create a file lib/book_store/book_state_hydrator.ex and add the following contents:
defmodule BookStore.BookStateHydrator do
use GenServer, restart: :transient
require Logger
alias BookStore.Books.Book
alias BookStore.BookDynamicSupervisor
def start_link(state) do
GenServer.start_link(__MODULE__, state, name: __MODULE__, timeout: 10_000)
end
@impl true
def init(_) do
Logger.info("#{inspect(Time.utc_now())} Starting Books process hydration")
BookStore.Books.all()
|> Enum.each(fn %Book{} = book ->
BookDynamicSupervisor.add_book_to_supervisor(book)
end)
Logger.info("#{inspect(Time.utc_now())} Completed Books process hydration")
:ignore
end
end
The only thing that I’ll point out here is that our init/1 callback returns an :ignore atom. This signals to the
supervisor that this process will not enter the process loop and that it has exited normally. After the process
hydration step is complete we no longer need this process so it is free to ride into the sunset :). Next we’ll want to
update our application.ex file to ensure that this runs and block prior to our Phoenix Endpoint process (here is the
whole child list for order reference given that the order is important):
def start(_type, _args) do
children = [
# Start the Ecto repository
BookStore.Repo,
# Start the Telemetry supervisor
BookStoreWeb.Telemetry,
# Start the PubSub system
{Phoenix.PubSub, name: BookStore.PubSub},
# Start the Book Store Registry
BookStore.BookRegistry.child_spec(),
# Start the Book DynamicSupervisor
BookStore.BookDynamicSupervisor,
# Hydrate process state
BookStore.BookStateHydrator,
# Start the Endpoint (http/https)
BookStoreWeb.Endpoint
# Start a worker by calling: BookStore.Worker.start_link(arg)
# {BookStore.Worker, arg}
]
...
end
Step 9: Writing Some Stress Testing Scripts - commit
In order to test the two different implementations of our application we will write a simple stress tester that
generates a random battery of requests to make against our API. The test suite is rather simple and will perform a
uniform distribution of queries (i.e every book has an equal chance of being interacted with). If you are feeling
ambitious, I would suggest writing a test suite that follows a Pareto distribution of queries where 20% of the books in
your inventory result in 80% of the traffic (definitely send me a Tweet and a Gist with some of your sample stress tests
if you do). This may be more indicative of real world traffic as some books are more popular than others. Let’s create a
file uniform_test.exs at the root of our project with the following contents:
:rand.seed(:exrop, {1, 2, 3})
:inets.start()
:ssl.start()
total_requests = 2_000
concurrency = 20
book_ids =
BookStore.Books.Book
|> BookStore.Repo.all()
|> Enum.map(fn %BookStore.Books.Book{id: id} -> id end)
request_book_ids =
1..ceil(total_requests / length(book_ids))
|> Enum.reduce([], fn _, acc ->
acc ++ book_ids
end)
|> Enum.shuffle()
|> Enum.take(total_requests)
|> Enum.zip(1..total_requests)
request_book_ids
|> Task.async_stream(
fn {book_id, count} ->
case rem(count, 3) do
0 ->
url = 'http://localhost:4000/api/books'
method = :get
:httpc.request(method, {url, []}, [], [])
1 ->
url = String.to_charlist("http://localhost:4000/api/books/#{book_id}")
method = :get
:httpc.request(method, {url, []}, [], [])
2 ->
url = String.to_charlist("http://localhost:4000/api/books/#{book_id}/order")
method = :post
:httpc.request(method, {url, [], 'application/json', '{}'}, [], [])
end
end,
max_concurrency: concurrency
)
|> Stream.run()
Next you can run the following commands in separate terminals to give it all a go. I would suggest opening up your
LiveDashboard instance and navigating to you Phoenix metrics
http://localhost:4000/dashboard/nonode%40nohost/metrics?group=phoenix:
# In one terminal
$ docker run -p 5432:5432 -e POSTGRES_PASSWORD=postgres postgres:12
# In a second terminal
$ mix ecto.reset && iex -S mix phx.server
# In a third terminal
$ mix run uniform_test.exs
Depending on the machine that you are running on and if you adjusted any of the constants at the top of the stress test
file, it may take a while to get through all of the test requests. Once you’ve gown through the test suite, open up your
books controller file at lib/book_store_web/controllers/book_controller.ex and swap the regular database style calls
for the actor implementations (rerun the previous sets of commands from scratch to ensure a fair side by side
comparison). Below are the results running on my MacBook Air with my database running in Docker. Focus more on the
relative performance number instead of the absolute performance numbers:
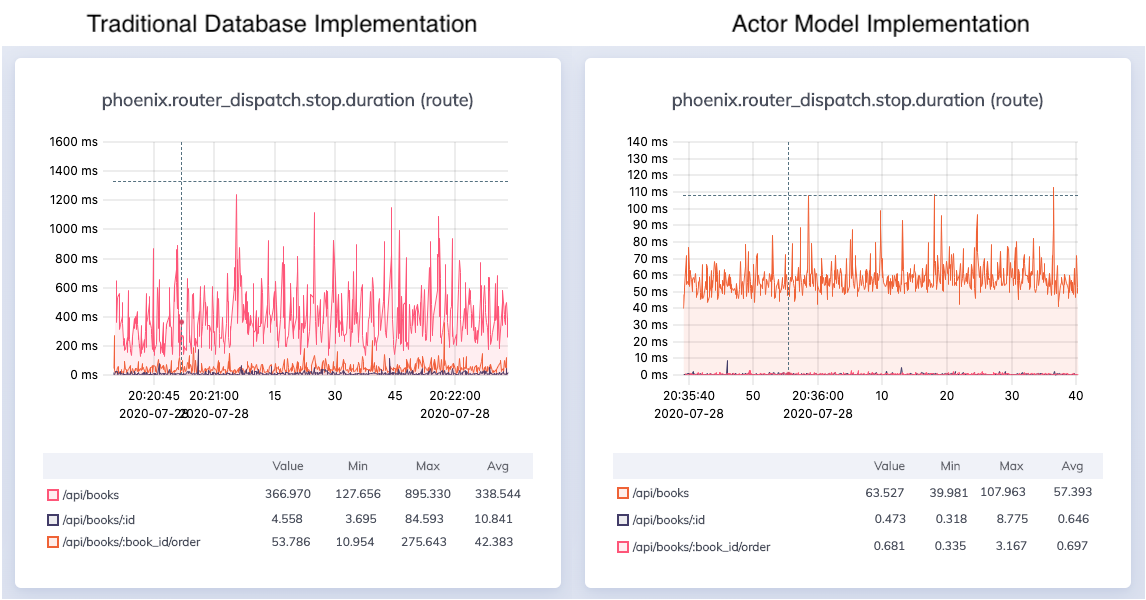
As we can see, our Actor Model implementation was able to handle the load in a far more performant manner. For example, fetching all the books from our inventory took an average of 338ms in the database centric implementation while only taking an average of 57ms in our Actor Model implementation. Our single book reads and writes took just over half a millisecond each in the Actor Model while in the database centric approach reading book information took 10ms and updating state took 42ms. In addition, our min and max request times had a far lower delta in the Actor Model approach compared to the database centric approach. It is also important to note that this is a “best case scenario” for the database implementation given that Postgres was running on my localhost. Rarely in a production system will your database be running on the same host as your application, so keep in mind that in a production context your database centric approach has to deal with network latency.
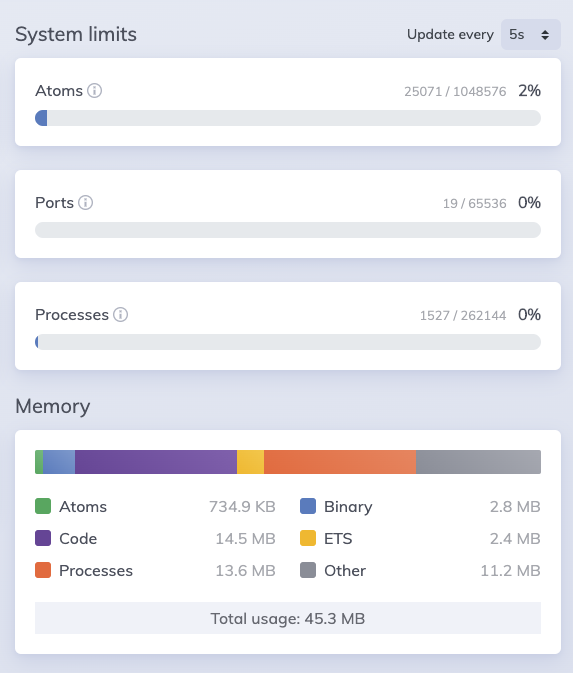
Another important thing to mention is the resource utilize of our Actor Model approach. If we look at the Phoenix LiveDashboard we can see that we haven’t even made a dent in our max allowed processes, and the amount of memory require to store our entire dataset in GenServers is rather modest.
Closing thoughts
Well done and thanks for sticking with me to the end! We covered quite a lot of ground and hopefully you picked up a couple of cool tips and tricks along the way. To recap, we implemented a traditional database version and an Actor Model version of our application and compared their performance characteristics under load. I encourage you to play around with both implementations and the stress tester and let me know what your findings are!
While we were able to realize very real gains in performance, I do want to make sure I supply the appropriate caveats to the presented solution. Firstly, the problem that we were attempting to solve was a good fit for the Actor Model. Each actor was independent and decoupled from the rest. If we find ourselves in a position where our actors are tightly coupled and the use of more complex transactions is required in order to maintain data integrity, we may need to rely on the constructs that are available to us via the database. Another important thing to note here is that we are grossly under utilizing our database. Things like full text search, geospatial search and even complex queries are a lot harder to perform from the proposed Actor Model solution. All this to say that this pattern should be another tool in your Engineering toolbox. Be sure to reach for it when the problem fits well into these constructs :).
Be sure to sign up for the mailing list and/or follow me on Twitter so you won’t miss the next article! Till next time!
Additional Resources
Below are some additional resources if you would like to deep dive into any of the topics covered in the post.
- [1] https://hexdocs.pm/elixir/Registry.html
- [2] https://hexdocs.pm/elixir/DynamicSupervisor.html
- [3] https://hexdocs.pm/elixir/master/GenServer.html#module-name-registration
- [4] http://erlang.org/doc/man/supervisor.html#start_link-2
- [5] https://medium.com/mytake/understanding-different-types-of-distributions-you-will-encounter-as-a-data-scientist-27ea4c375eec
comments powered by Disqus